 DE
DE  EN
EN 
This function is currently only implemented on Windows based platforms! Another method for job splitting is available using the OutArchiveDir key. An overview of different job distribution methods can be seen here.
ERP systems typically produce through their batch printing processes huge print jobs, like for example invoices. Sometimes it is needed to separate them into single jobs.
-
Staple each individual job, see Examples
-
Archive and search each individual jobs, see Examples
-
Send out each individual job as an e-mail or fax
-
Workload balancing for splitting huge jobs to several printers, of you like even with different speeds, so that the job is printed in minimum time. (see manual for detailed explanations and here)
The technology how ELP handles the print job splitting is pretty easy:
-
Receive the job on windows queue 1
-
Instead of printing the job to the printer, send it to another or tagged as the second pass to the same windows queue
-
Search for the last page of each individual job (first page search process is in development) and
-
Split it right after the next form feed by closing the out-writing and re-open the writing again. So a new job is generated in the receiving queue
Jobs with a fixed amount of pages per single document do not need to search for a fixed statement on the last page. There are other ways to do it, see below.
The supplied rule assistant way of splitting files does not work for jobs which have already the split escape sequence build in, see below.
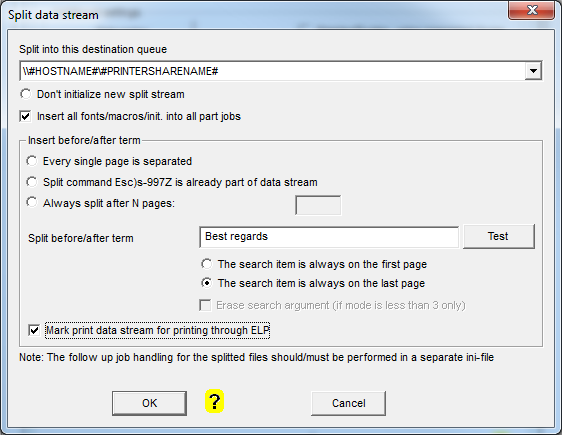
Select in the drop down list the destination queue for splitting the job, but make sure, it is NOT the same queue which receives the files. Define the split method by single pages or search for a term. Maybe make sure with the function New Rule/Section that the search method Search_Windows can find the text. If not you may need to change the statement later to Search_:Windows_New.
Press the OK and the back button. 2 new rules are now available:
-
Split file using OutPort method
-
The rule for the destination queue
If you solutions requests to apply for all split jobs the same functions, you may add them now to the printer names rule. But if you need to develop several rules to the split jobs, generate a new file called split.ini in the folder c:\ProgramData\WELP and load it into the ELP Control Center. An new ini file can be created by copying for example the convert.ini or simply create a new empty file with Notepad.
Limitation
- The splitting of spool files directly into an archive or for further processing in another queue is not support at the same time using the SAP Unicode conversion. This solution is first to split into a queue and using a second run of each split document together with the SAP Unicode replacement.
- In case the data stream does already contain the Macro ID definitions (here 100) and this Macro is called on several pages on split documents: The ID definition sequence has to be defined in a stand alone sequence. Combining the sequences for ID and call like Esc&f100y3X (or 3X or 4X) might not work, as ELP does not insert the Macro content in the followed split document parts.
Technical background
The fill options for this "Split a data stream" Window are:
| Split into this destination queue |
Here ELP offers 2 options:
Notes:
|
| Don't initalize new split stream | In very rare cases (rare especially windows data streams), the mail merge pages are generated in a way, that they can be printed fully stand alone. In that case you may set this option |
| Insert all fonts/macros/init. into all part jobs |
Turned on, ELP automatically reinitialize the split jobs to the proper values, that the document is stand alone printable.
|
In order to separate the jobs, ELP needs on each individual last page a trigger in form of an escape sequence, like <Esc>)s-997Z where <ESC> is ASCII 27 or hex1B, or using the Free-Escape feature of ELP: ~)s-997Z. If you can add this sequence already to the job, then no search is needed. You can apply the OutPort rule direct in the receiving rule and add EXIT=ON to finish the ini file analysis.
| Every single page is separated | The document has to be split after each page. An N page document will then lead into N+1 split documents. There is one more document split, because after the last form feed |
| Always split after N pages | The single document does have always exact N pages (2 and up). Then ELP will split the document using an ELP_Command: C1:#F25997R0; where # is the amount of pages. (Module FOR is needed) So on every # page the escape sequence \x1B)s-997Z is added by the ELP command F25997, which is a dummy macro and does only hold that ELP internal PCL command. The R command resets the page counter to 0, so that the next page is page 1. |
| Split command Esc)s-997Z is already part of data stream | The needed split command is already added by your application, e.g. MS Word. |
| Split before/after term | If the amount of pages of the single document variate, and do not have the split sequence in, then search for a special expression in the data stream and add the split information using a rule. Please use the test function to be sure that the expression/term is findable be ELP the new rule option and add them like the prototype below. ELP can handel an indefinit amount of rules for searching ans spitting different data streams. You can add them later using the standard rule generator. |
| Test | This button ensures, that the entered expression is found in the data stream. Before pressing the button, the data stream first needs to be stored or printed into a file. You can use the protocol option of ELP (file in_data.prn) or simply print the job to file. See here for ways how to get the files outside from ELP. This function is not only looking for the term, but also with which method it needs to be searched. |
| The search item is always on the .... | first page : Means that the entered search expression is always on page one of each split document. ELP then does automatically insert the split command before the last formfeed. (The key Preparsing needs to be turned on in rule Global) (The miscellaneous key: Preparsing=ON needs to be set in rule Global) last page : Means that the entered search expression is always on the last page of each split document. This is the faster process method compared to first page. If search method is Binary, Windows or Text (not _new), preparsing can be turned OFF. |
| Erase search argument (if mode is less than 3 only) |
If needed and if the search mode is Search_Binary, _Windows or _Text (not _New), the searched expression can be removed from the data stream. |
| Mark print data stream for printing through ELP |
When the split data stream returns to the same ELP queue, a marker needs to be in the returned document, that ELP has the chance to detect a second pass and apply the requested rules. Marked, the ELP Control Center wizzard does add those 2 rules: [Split same queue pass 1] REM=Mark print data stream for printing through ELP [Split same queue pass 2] REM=Use the following ini file for second pass through ELP NOTES:
|
More technical aspects
Split mailmerge print files in their single documents. Additional technical information how streams are split can be found here.
Related articles: Split a big job into 50 pages pieces, as this is maximum amount of pages being stapled, Split a job to different out-trays and perform rules upon used input trays, New Rule/Section