 DE
DE  EN
EN 
Archiving means to ELP, storing the incoming data stream or the generated output including all printable information, like bar code and forms, to a folder. The power of ELP variables can be used to create dynamic folders or to generate file names and even index files if needed.
Find here on this page:
-
A description of all options W-ELP Control Center archive menu in the rule assistant provides
-
What you can do with the archive command, e.g. split direct a huge mail merge print job into it single documents
-
How ELP supports a so called MyPrintArchive function, where you can store all or just a selection of print files, and finally print them to any printer, in one shot. So no other job can interfere.
-
How to place the archive folders on another PC/Server:
-
Generate index files
-
Collect4Printing including postal optimization for adding maybe even OMR marks
-
and much more.
But first let us have quick look into the possibilities of the ELP Control Center menu for archiving Configuration Tab - rule assistant:
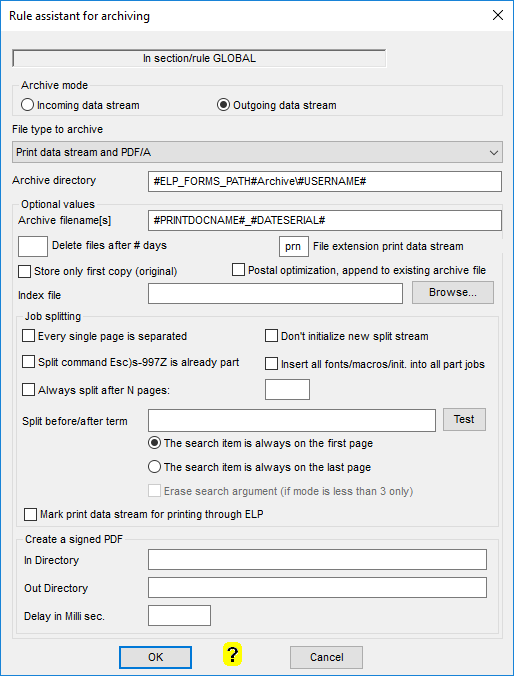
| Incoming data stream | If selected the incoming data stream is stored into the named folder. It is recommended to set this option only in triggered rules, as until then you may have collected all needed Variables. The disadvantage: Search and add/replace/insert or delete commands might have been already processed at that point. |
| Outgoing data stream | Same remarks as above, but for outgoing data. If there are no special searched Variables in the storage path, you can set the command even in the rule GLOBAL |
| File Types to Archive | You may choose between TIFF, PDF including on request the PCL5 data stream. For reprinting or postal optimization, the data stream must be archived! |
| Archive Directory | Any path can be used. The default path is the Workpath c:\ProgramData\Welp\archive. Be sure, that the folders are accessible for the user system. If you like to store the results on another server, use the UNC name like: \\servername\sharename\path. Set the security for the user system and the #PCNAME# of the sending PC at the destination folder or set in the admin registration tab the "Process User" to "Current" user or define a "Named" process user. If you like to get a new folder for every day, add the key #DATETEXT# in the path. Hint: Outside of the splitting function it is recommended to call the archive function in a triggered rule: This ensures that all needed variables are fully collected. |
| Specific names for | A requested file name. By default any duplicated file name will be avoided by automatically adding _1, _2 etc. to the file unless the option postal optimization is used. A good way to avoid duplicated file names is to add the variable #DATESERIAL# to the file name. It is recommended to have always archive file names with a three character file extension. Like for example .PDF or .PRN. |
| Delete files after # days | You should enter minimum 14 days. As there are maybe weekends and/or public holidays |
| File extension print data stream | If the print file will be archived you can define a file name extension. Common choices are pcl and prn. |
| Store only first copy | In most cases there is no need to store the amount of printed copies. Just the first copy (= original) is enough. |
| Postal optimization | This is used to save postal money and mostly in conjunction with printing OMR marks on the pages, the archive function is used to store the jobs for a certain period of time, and if a job name is found twice, then the new job is added. So at the end one archive file can hold several jobs (= invoices/delivery notes etc.) The trick is to generate a unique file name for every item. If the post requests the mailing in ZIP order, then start the file name with the zip number, maybe followed by the delivery address number or city, state and customer name variables. A special job then can start the print. |
| Index file | Archiving to professional storage system using Index files |
ELP is able to split files directly and fast into an archive folder: Please note that splitting and postal optimization in one step is not possible. For this please first split the job and then archive each single document in a second step.
| Every single page is separated | The document has to be split after each page. An N page document will then lead into N+1 split documents. There is one more document split, because after the last form feed |
| Always split after N pages | The single document has always exact N pages (2 and up). Then ELP will split the document using an ELP_Command: C1:#F25997R0; where # is the amount of pages. (Module FOR is needed) So on every # page the escape sequence \x1B)s-997Z is added by the ELP command F25997, which is a dummy macro and does only hold that ELP internal PCL command. The R command resets the page counter to 0, so that the next page is page 1. |
| Split command Esc)s-997Z is already part of data stream | The needed split command is already added by your application, e.g. MS Word. |
| Split before/after term | If the amount of pages of the single document variant and the data stream do not have the split sequence already inserted, then search for a special expression in the data stream and add the split information using a rule. Please use the test function to be sure that the expression/term can be found! ELP can handle an indefinite amount of rules for searching and splitting different data streams. You can add them later using the standard rule generator. |
| Test | This button ensures that the entered expression is found in the data stream. Before pressing the button, the data stream first needs to be stored or printed into a file. You can use the protocol option of ELP (file in_data.prn) or simply print the job to file. See here for ways how to get the files without ELP. This function is not only looking for the term, but also with which method it needs to be searched. |
| The search item is always on the .... | first Page: Means that the entered search expression is always on page one of each split document. Then ELP automatically inserts the split command after the last form feed. (The miscellaneous key: Preparsing=ON needs to be set in rule Global) last page: Means that the entered search expression is always on the last page of each split document. This is the faster process method compared to first page. If search method is Binary, Windows or Text (not _new), pre-parsing can be turned OFF. |
| Erase search argument (if mode is less than 3 only) | If needed and if the returned search mode of the Test option is Search_Binary, _Windows or _Text (not _New), the searched expression can be removed from the data stream. This option is only accessible after the test function did hit the searched term with one of the 3 search methods above. |
| Mark print data stream for printing through ELP | When later on the split archived data stream may returns to any ELP enabled queue, a marker in the returned document lets ELP detect this second pass and apply the requested rules. Marked, the PPAdmin wizard adds these 2 rules:
[Pass 1 Archive and splitting same queue] REM=Mark print data stream for printing through ELP [Pass 2 Archive and splitting same queue] REM=Use the following ini file for second pass through ELP NOTES:
|
In addition each PDF file can be digitally signed by an external software. PDF/A is supported by the supplied PDF converter and can be controlled in the file PDFConf.ini in the Workpath (e.g. C:\Program\Data\Welp).
| Generate a signed PDF | If you have a 3rd party digital signature software, the PDF can be signed and e-mailed or archived. For that process simply enter the process folders, everything else is hard coded in ELP. This function is only usable within a Windows environment. |
Additional keys which are not available in the user menu:
| SplitAfterEachCopy | This key is only usable with the command keys OutArchiveDir or OutPort and the ELP_Command copy option K#;. Turned on, the job is split after each copy. |
Hint:
The W-ELP Control Center can be installed (actually copied) to a network device, so that everybody has access to it. Done in the proper way, the Control Center will only list this tab and all the others are not shown. So nobody can manipulate the actual ELP installation. If the variable #USERNAME# is used in the path description, it is replaced by the actual user name and so it is assured, that no other user can have a look into owned print jobs.
The full documentation is here: Configure the W-ELP Control Center reprint tool on a normal user PC or on a Network drive .
Additional technical information how streams are split can be found here.
Technical Information:
Limitation
The splitting of spool files directly into an archive or for further processing in another queue is not support at the same time using the SAP Unicode conversion. This solution is first to split into a queue and using a second run of each split document together with the SAP Unicode replacement.
Troubleshooting
If the data stream is NOT split, but the archive file or PDF is twice generated, then in most cases the rule which actives the archiving is executed twice. Maybe add the key: Search_only_once=ON in the rule, or if the searched text needs to be erased every time.
[Search Archive Trigger Text]
Search_Binary=!wwww!
Erase_Binary=ON
OutArchiveDir=c:\Archive;#INVOICEVARIABLE#_#ACTTIME#.prn
Search_Only_Once=ON
[Search remaining Archive Trigger Text]
Search_Binary=!wwww!
Erase_Binary=ON
ReadOnlySearchKeys=ON
How to place the archived files on another PC/Server
e.g. on a shared folder on another PC/server this will be mandatory:
Use the UNC name for storing the files: \\servername\sharename\folder;fileName
Set the access rights for the folder for the user EVERYONE and for the ELP server
a) the USER <COMPUTERNAME> and end the name with a Dollar! E.g.: MYPCNAME$ (make sure that the object type computers is included)
b) for the user SYSTEM of the ELP server.
Alternatively you may set in Admin Tab the "Process User" to "Current" or define a "Named" process user and apply this setting. Then the user needs to have the access rights and the PC as well. However, this is NOT guaranteed to work, as if the ELP processing might not be started under the user settings, ELP switches to the default mode (System user) without any notice. Only debugging the welpprint.dll may show with which user the process was started. This can be enabled in the Admin Tab as well.
Archive Non PCL5 files
Any file can be archived, if the commands are listed in one of the default activated rules: Global, user-, printer-, driver- or port-name. If the rule setting needs to set all non PCL5 streams to be archived, you may set the In- or OutArchiveDir Command also in the rule PassThrough.
This is the fastest method to store a copy of the out data stream to any reachable server and folder. Another benefit is the possible documentation of the archive file name in the reporting file, as the full file name of the last archived file is available in the ELP variable #LAST_ARCHIVE_FILE#. This "database" may help to find the proper file a little quicker for reprinting purposes.
The generated files are named by default exactly the same as the out data file. The printing date and time are added to the file name, but this automatism can be turned off using the key ArchiveFileNameWithoutDate=ON.
; only for local volumes! The user system does NOT know any shared network volumes
OutArchiveDir=D:\ARCHIVE
; on other PCs/Servers, see security information above
OutArchiveDir=\\SERVER\ShareName\Dir
The key entry cannot only define the folder, it can also influence the file name. The definition is optional and has to be separated from the folder name by a semicolon. The new name could be fixed like FILENAME.EXT, but can also be based upon any ELP [collected] variable. This is pretty powerful, as the you may encode for example an invoice number even together with the delivery number. In fact any variable known to or collected by the system can be used, even in the path. Missing existing folders are automatically created.
OutArchiveDir=#ELP_FORMS_PATH#ARCHIVE;TEST.PRN
This example might look pretty stupid because every print job seems to be stored into the same file c:\ProgramData\Welp\archive\test.prn. This is in fact is NOT true, as if ELP finds the destination file already existing, it adds by default an integer number to the file name for the second and further stored jobs.
; The separation character _ can be changed using the key UniqueFileNameChar exclusively in the section GLOBAL.
"..\test.prn" "...\test_1.prn" "...\test_2.prn;" etc.
; This is a little improved, because now the date is encoded into the file name, but still only one file per day: "d:\archive\test 25.11.2003.prn"
OutArchiveDir=D:\ARCHIVE;TEST_#DATENUM#.PRN
; Now even the seconds are encoded into the file name, 12:24:50
; "d:\archive\test 25.11.2003.12_24_50.prn"
; As the colon character is not allowed in the file name, it is automatically replaced by the underline sign.
OutArchiveDir=D:\ARCHIVE;TEST_#DATENUM#.#ACTTIME#.PRN
; Same thing, but shorter file names and the username is also encoded.
OutArchiveDir=D:\ARCHIVE;#USERNAME#_#DATESERIAL#.PRN
What happens if ELP processes 2 jobs in different queues at the same time ELP might loose one, which can be avoided through the following tricks:
-
Use the JobCounter as a 100% unique number in the file name
[Global]
JobCounter=#ELP_FORMS_PATH#JobCounter.var
OutArchiveDir=D:\Archive;Test_#JOB_COUNTER#.prn -
Encode also the random file name, generated by the windows system:
OutArchiveDir=D:\Archive;Test_#IN_ELP_FILENAMEWITHOUTATH#.prn
-
An even better way is to collect a unique number like invoice number out of the data stream and use this number in the filename.
[Search Invoice Number]
Search_Binary=invoice No.:
StoreNextWordToVariable=#INVOICEVARIABLE#
ReadOnlySearchKeys=ON
Search_Only_Once=ON
[Global]
OutArchiveDir=c:\Archive;#INVOICEVARIABLE#_#ACTTIME#.prn
-
Use the random variable:
OutArchiveDir=c:\Archive;#DATESERIAL#_#RANDOM#.prn
Note: If the file name already exists, ELP will still add the differentiation number to the file name, to make it unique
Additional available keys not handled in the example further down:
| CloseArchivesBeforeCall | Set this key, if you would like to have access to the actual with OutArchiveDir stored data stream. Maybe for resending it in a sorted order to a port. |
| CloseArchivesBeforeInsert | Set this key, if you would like to have access to the actual with OutArchiveDir stored data stream. Maybe for resending it in a sorted order to a port. |
| ClosePortsBeforeCall | Set this key to ON, if the job distribution should be stopped before the Call[NoPrint] commands. |
| ClosePortsBeforeInsert | Set this key to ON, if the job distribution should be stopped before the InsertAtJobEnd[DoNothing] command. This key will prevend that loaded files are inserted into the distributed data stream. |
| DoNotPrintDataStream | Only usable with CallReadback, InsertPrintFilesAtJobEnd[DoNothing] or specific ELP_Commands as EE or EX. The print stream is processed using all applied rules, but is NOT printed out. Only the after processing commands generate print output. |
| ArchiveDays | Data streams older than the given days are automatically erased |
| InsertPrintFilesAtFormFeed InsertPrintFilesAtJobEnd InsertPrintFilesAtJobEndDoNothing |
see example: Collect4Printing |
| Any matched files from the given archive folder are inserted and deleted at the end of the job, but before the ELP EE### command IMPORTANT NOTE: As each job is loaded separately, only one job at a time must fit into the RAM of the PC |
|
| Same functionality as key above, but the data stream is passed through and does not run anymore through the ELP process | |
| IllegalCharInFileName | Especially when file names are build from variable data, illegal characters like : or \ need to be replaced. The default replacement character is the _. But using this key, you can use any other character.Note. Do not define any illegal characters, this will cause an endless program loop |
| UniqueFileNameChar | If postal optimization is turned off (default) ELP will generate unique file names when storing new files using a name for which a file name already exist. by default the character _ is used to add a unique file number to the file name. The separation character _ can be changed using this key |
The key PDF_Mode defines in which format the archived data stream is stored or sent.
Format specific adjustments for PDF can be controlled globally in the file PDFConf.ini stored in the Workpath (e.g. C:\Program\Data\Welp). Once workflow specific adjustments must be made the key PDF_Arguments can be used.
Format specific adjustments for TIFF must be made using the key TIFF_Arguments.
The first Example is located by continue reading on the other page.
OutArchiveDir splits mail merge document into it single documents
ELP is also able to split mail merge print jobs archive files. It is the exact same thing then splitting the file using the OutPort key the OutArchiveDir key has to be used the key OutArchiveSplitFiles=ON does activate the splitting. Once the split Sequence is detected, the outgoing job is stored in a unique file names. Up to 64000 single split files can be generated.
See Example: Split mail-merge print files in their single documents> OutArchiveDir mode for detailed description.
OutArchiveDir archives only one copy
ELP also supports to write only one copy to the archive, even the ELP_COMMAND defines multiple copies using the K#; command. Use the key
OutArchive_Only_One_Copy=ON
in the same section like the OutArchiveDir or the database open key.
R or Q copy factor commands are currently not performed correctly! If needed contact your local distributor.
OutArchiveDir performing the MyPrintArchive function 
Another solution for archiving and collecting data streams for reprinting, even sorted using the Archive Tab
Example: MyPrintArchive
OutArchiveDir: Collect4Printing 
In the first step all data streams are per default collected in an archive folder. After a special trigger expression is found in a special trigger data stream all jobs are printed and erased. This trigger expression could be easily send to the printer for example using a batch command, which print a predefined text file, containing the trigger expression.
OutArchiveDir: Collect4Printing, sort and postal optimize and maybe automatically print and add OMR marks
To save quite some money, (beside sending the jobs via> Fax or E-Mail) ELP can collect all mails throughout the day, Sort them according to customer and finally print the packages including OMR marks.
Postal optimisation and OMR marking
OutArchiveDir: Database handler
If a search in a database is performed, the record is found and
-
the record contains a field called OUTARCHIVE
-
The field is filled with an OutArchive argument
Then ELP will also store the print file automatically into the provided path and file name. No PDF or TIFF conversion is applied.
Works like the OutArchiveDir method with this exceptions:
-
The variable #LAST_ARCHIVE_FILE# is not set for accounting and other stuff.
-
No splitting into different archive names
-
OutArchiveOnlyOneCopy cannot be used
-
The database field is called INARCHIVE
InArchive-keys can be used as often as needed, but if the original data stream should be copied, then put the commands in one of the default activated sections: [GLOBAL], [PrinterName], [UserName].
Note: If the command is activated after some SEARCH_xxx rules did already perform Add_, Insert_, Replace_ or Erase_binary commands, those changes will remain(!) in the stored data stream.
[Archiving incoming data stream]
Search_Windows_New=Invoice No.
; attention, stores it on an external server, set correct access rights for user SYSTEM! See above
inarchivedir=\\ArchiveServer\ELP_INVOICES
; archive PDF + PJL job
PDF_MODE=4
; so advice that only PDF is stored
ARCHIVEMODE=2
This key ArchiveMode defines the type of files are stored in the archive folder:
0 Only Data Stream or definition of key PDFMODE;
1 PDF File is generated, print file and PDF file are stored;
2 only PDF file is stored, print file is erased
Archiving to professional storage system using Index files 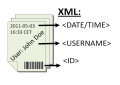
Professional archiving software packages mostly work by polling the content of a folder and add automatically the found files into its system. In order to give users later access to the files, the systems stores applicable additional information in a database.
As ELP is able to find any searchable data in the data stream, and stores it into variables, it is very easy to generate automatically fully freely designable index files. They have the same naming as the stored print / pdf / tiff file, but usually another extension. (HPS or XML).
If the destination file name already exists, a counter _1, _2 etc is added to the file name. It is recommended to have always archive file names with a three character file extension. Like for example .PDF or .PRN.
See here for a nice example: Archiving to professional storage system using Index files
Insert stored print files into the data stream
On this pages are quite some possibilities listed how that can be achieved, Anyway in most cases those keys are used.
| InsertPrintFilesAtJobEnd | Any stored files will be added at the end of the job. Note:
Example: InsertPrintFilesAtJobEnd=d:\archive\#USERNAME#\*.* |
| InsertPrintFilesAtJobEndDoNothing | Same as described above, but the file is not processed by ELP, just passed through. A second difference is, that the complete file is inserted outside of the ELP_Command ET; so it is NOT wrapped in PGL! |
| InsertPrintFilesAtFormFeed | Same as described in the top row, but performed at the next found form feed in the data stream. Could be used for inserting data sheets into mail merge documents, which had been for example even generated on the fly. |
| InsertPrintFilesNow | Same as described in the top row. Could be used also with Erase_Binary or Replace_Binary which will be executed before the insertion. Note: It is not allowed to use Exit=ON an Passthrough=ON in the same rule. If needed create a new rule, use Search_ or Trigger_ and there you can perform Exit= or Passthrough= |
If the actual data stream was archived in order to get it into the correct print rowing, then use those two keys:
| CloseArchivesBeforeInsert | To have full access to the right now stored file |
| DoNotPrintDataStream | Dump the just process print job, as it will be refead with the InsertPrintFilesAtJobEnd[DoNothing] key |
Some more archiving tricks with ELP
1. Sorting different spool files maybe form different systems and print them in the correct order
A: Answered here. We also can provide examples for more then 2 jobs, using document counters.
2. We would like to generate archive with the filename containing a invoice number
A: Search in the data stream for the word or position escape sequence before the invoice number or any other item you want to use. Then read the following word into a variable, which is e.g. the invoice number and use this variable in the OutArchiveDir key.
[invoice]
; define what stands in front of the item you need to store
Search_Windows_New=Invoice No.
; if found the next word is stored into the provided variable
StoreNextWordToVariable= #InvoiceNo#
; ELP will generate in the path d:\archive a file with the invoice number extension.prn
OutArchiveDir= d:\archive;#InvoiceNo#.prn
3. Can I also store the data using the USER Name as a file name?
A: Yes, ELP does have a quite number of predefined variables. One of them is #USERNAME#. It contains the user who is printing which can also be found in the job properties of the Windows queue.
[HP LaserJet Universal PCL5]
; Whatever is printed through this driver is stored in an archive
; In order to get a file name for each job ELP adds the actual date
OutArchiveDir=d:\archive;#USERNAME#_#DATENUM#_#ACTTIME#.prn
4. I know, I can make for every printer an own archive directory, I also can make a section for every user and archive the data in a user dedicated directory, even on his PC, but isn't there a simpler way so I don't need to add N user sections?
A: Yes there is. The following example will store every job (Section Global) in a dedicated user directory. As a filename the example below even uses the Document name.
[GLOBAL]
; In order to get a file name for each job ELP adds the actual date
OutArchiveDir=d:\archive;#USERNAME#\#PRINTDOCNAME#_#DATENUM#_#ACTTIME#.prn
Notes:
-
The directory must be available for all users. Directories are automatically registered.
-
The PPAdmin Archive Tool does currently only support the command up to the first semicolon. So sub-directories merged in with variable contents is not yet supported. The routine will not find them.
-
You may of course combine Example 2 and 4.
Hint:
If you print in an MS Windows environment using HP drivers, you can also get some nice information out of the print data file.
[invoice]
Search_Windows_New=Invoice No.
StoreNextWordToVariable= #InvoiceNo#
ReadOnlySearchKeys= ON
; Using the default user name:
OutArchiveDir=d:\archive\#USERNAME#;#InvoiceNo#.prn
; or:
[Search myUserName]
Search_Binary= JobACCUsername:
StoreNextWordToVariable= #MyUserName#
; ELP will generate in the path d:\archive a file with the invoice number extension .prn
OutArchiveDir=d:\archive;#MyUserName#\#InvoiceNo#.prn
Note: If the username in the print file ends with an illegal file name character like " (double quotes), ELP replaces this character with a _ (underscore). So the folder name for example will be d:\archive\JohnDoe_\4711.prn
Related articles: Archive Tab, Running convert.exe process in user context, Archiving to professional storage systems, Example: MyPrintArchive - Collect4Printing